

前回書いたCognitive Toolkit(CNTK)のハンズオンを行っていた際にGPUマシン※の凄さを体感しました。
私はGPUマシンを利用、他の人が実行した環境はGPUを利用しない環境。実際に同じものを実行してみると、 処理時間に大きな差が!
本当にそんなに違うのか、もう一度確認のために、Azure上でCPUオンリー用のVMマシンを構築して比較してみました。
※GPUマシンは、コンピューターの性能を向上し、Deep learning(深層学習)の計算性能向上をサポートします。
まずはGPUマシンの方ですが、前回構築したものをそのまま使用。もう一方の仮想マシンも、すでに環境が用意されているVM(Data Science Virtual Machine for Windows)があるみたいなので、そちらを選択。
VMイメージの詳しい内容はこちら↓
https://docs.microsoft.com/ja-jp/azure/machine-learning/machine-learning-data-science-provision-vm
サイズは前回のマシンに近いものを選択。
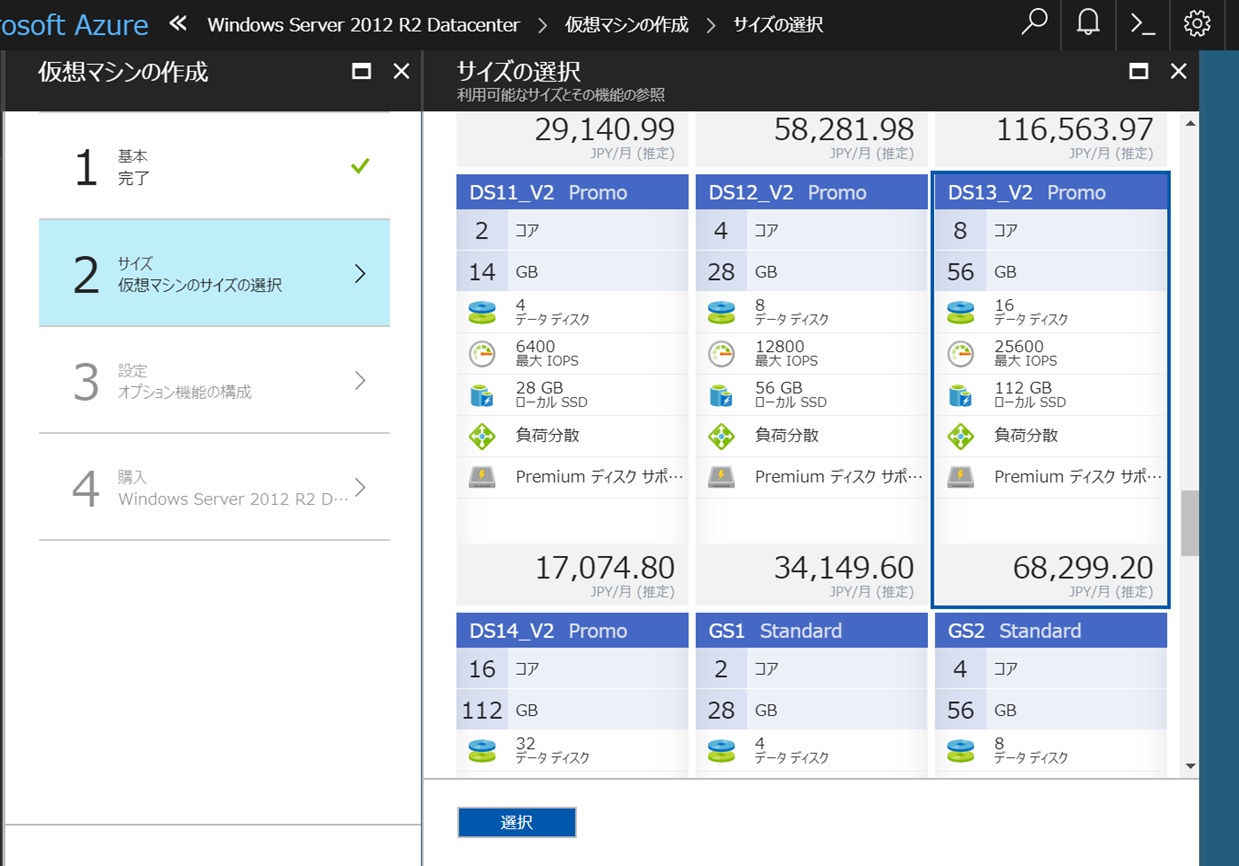
(画像をクリックすると大きな画像を表示します)
あっという間に環境完成!
環境ができたところで、早速速度を比較しようと思いますが、今回はCNTKのチュートリアルにあるCNN(Convolution Neural Network)の「CNTK_201B_CIFAR-10_ImageHandsOn」を利用してその中の学習処理速度を比較してみたいと思います。
まずは、チュートリアルを動かすために、jupyter notebookを起動。
と、その前に、VMの初期状態ではjupyter notebookは無効になっているらしく、まずは、デスクトップ上に置かれている「Jupyter Set Password & Start」ショートカットをクリック!

{kind=link}
(画像をクリックすると大きな画像を表示します)
コマンドプロンプトが表示されますので、任意のパスワードを設定。
(画像をクリックすると大きな画像を表示します)
次に、デスクトップ上の「Jupyter Notebook」をクリックして起動。

(画像をクリックすると大きな画像を表示します)
ブラウザが立ち上がり、このような画面が表示されます。
(画像をクリックすると大きな画像を表示します)
1.データ準備
初期画面から「CNTK-Samples-2-0」→「Tutorials」と進むと、様々なチュートリアルがあります。
この中で今回利用するのは、「CNTK_201B_CIFAR-10_ImageHandsOn.ipynb」ですが、そちらを実行する前に、
データを準備する必要があります。ということで、「CNTK 201A Part A: CIFAR-10 Data Loader」をクリック。
こちらを進めていくと、こちらから↓
https://www.cs.toronto.edu/~kriz/cifar.html
トレーニング用(50,000ファイル)、テスト用(10,000ファイル)の画像をローカルフォルダに取ってきます。これでデータの準備完了。
2.実行
まずはGPUマシンの環境で実行。 「CNTK_201B_CIFAR-10_ImageHandsOn.ipynb」をクリックします。
こちらを上から順に進めて、「create_basic_model」でトレーニング実行。
速い!平均8秒、1秒間に約6000のデータをトレーニングしてます。

(画像をクリックすると大きな画像を表示します)
では、同様にCPUマシンで同じように「create_basic_model」のトレーニング実行
・
・
・
終わらない。。。
あれ?
・
・
終わった!平均3分54秒。1秒間に約240のデータをトレーニング。
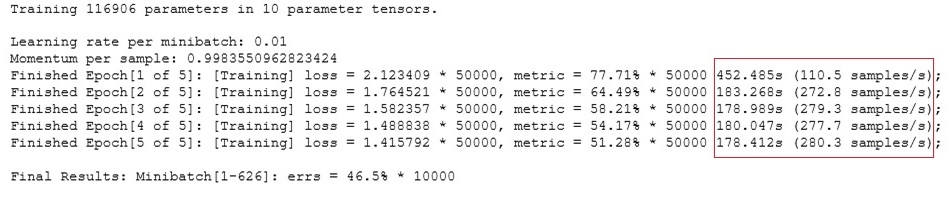
(画像をクリックすると大きな画像を表示します)
ということは、約25倍もの速さの違いがあることに!!
別のモデルも同様に比較してみましたが、やはり24~25倍の違いがありました。
結論
やっぱりDeep Learning(深層学習)を実行するならGPUマシン!
という結果になりました。